Parece que todas las empresas de tecnología están utilizando el enseñanza involuntario en estos días. O, al menos, dialogar de ello. Es un concepto de vanguardia que está recibiendo mucho revuelo. ¿Pero qué significa positivamente? En esta publicación, primero explicaré los conceptos básicos de lo que significa el término y luego cómo Riskified utiliza el enseñanza involuntario para impulsar la precisión al examinar pedidos por fraude.
¿Cómo sabe Netflix lo que quiero ver?
¿Por qué Netflix es tan popular? Sí, tienen una gran selección de películas antiguas y su contenido innovador sigue mejorando. Pero una de las características que positivamente los distingue de la competencia es la precisión de sus sugerencias de visualización, adaptadas a su sabor en función de lo que ha conocido anteriormente. A veces se siente como si supieran exactamente lo que quieres ver. ¿Cómo lo hicieron?
La respuesta, como probablemente haya adivinado, es el enseñanza involuntario. Pero ayer de explicar qué significa este término, entendamos la alternativa:
Ayer de la arribada del enseñanza involuntario, escribir código para producir sugerencias de películas personalizadas era una tarea difícil. Un programador tendría que escribir reglas si/entonces explícitas para cubrir una escala casi infinita de posibilidades. Un ejemplo simplificado: si la última película que un sucesor vio hasta el final y recibió una calificación reincorporación fue una comedia, sugiera la comedia más popular en el sitio que aún no haya conocido. Al programar miles de reglas como esta en un árbol de decisiones, Netflix podría gestar un flujo constante de recomendaciones de títulos.
Pero, ¿es esta la mejor guisa de hacerlo? Probablemente no. Por un banda, la tarea de atreverse y programar estas reglas es extremadamente engorrosa. Por otra parte, el cálculo puede funcionar tan perfectamente como las reglas que decida el programador. E independientemente de cuánta investigación o intuición tenga a su disposición el programador, es muy poco probable que comprenda todas las variables que deben tenerse en cuenta al atreverse sobre una recomendación, así como además cómo se deben ponderar estos diferentes puntos de datos.
En otras palabras, sugerir constantemente la mejor película a un espectador es una tarea tan compleja que está más allá de la capacidad de una persona, o incluso de un especie de personas. Y así, un cálculo al que las personas le digan explícitamente cómo comportarse estará sujeto a las mismas limitaciones.
Aquí es donde entra en distracción el enseñanza involuntario. En oficio de decirle a la computadora cómo dar recomendaciones, los programadores pueden fomentar el cálculo con datos históricos y dejar que la máquina aprenda cómo hacer recomendaciones de la mejor guisa.
¿Cómo “aprenden” las máquinas?
Hay muchos subcampos de enseñanza involuntario, pero detrás de todos ellos hay una idea básica: en oficio de decirle a una computadora cómo resolver un problema, muéstrele información relevante y deje que descubra la mejor guisa de resolverlo.
Entonces, lo primero que tuvo que hacer Netflix fue compilar una tonelada de datos detallados. Cosas como: qué títulos había buscado un sucesor; metadatos en los títulos que habían conocido (actores, directores, año de estreno); datos externos sobre el sucesor como demografía, región e idioma; y mucho, mucho más.
En esencia, lo que hicieron los arquitectos del sistema fue preguntarle a la máquina: en el pasado, ¿qué tan bueno como predictor era cada uno de estos puntos de datos al tratar de encontrar otra película que le gustaría a este sucesor?
El proceso para desarrollar un cálculo de detección de fraude (del que hablaré con longevo detalle más delante) es muy similar. Le mostramos a una computadora millones de pedidos, todos los cuales están etiquetados como legítimos o fraudulentos, y le pedimos que determine retroactivamente cómo se podrían activo considerado y ponderado mejor los puntos de datos del pedido para durar a la evaluación correcta.
En cualquier caso, el cálculo resultante no se desarrollará por reglas, sino que se basará en tendencias históricas sobre millones y millones de vistas de películas o pedidos de compras en ruta.
El funcionamiento interno de cómo una computadora puede durar a este cálculo aprendido puede ser extremadamente complicado, pero podemos usar un ejemplo simplificado para tener una idea.
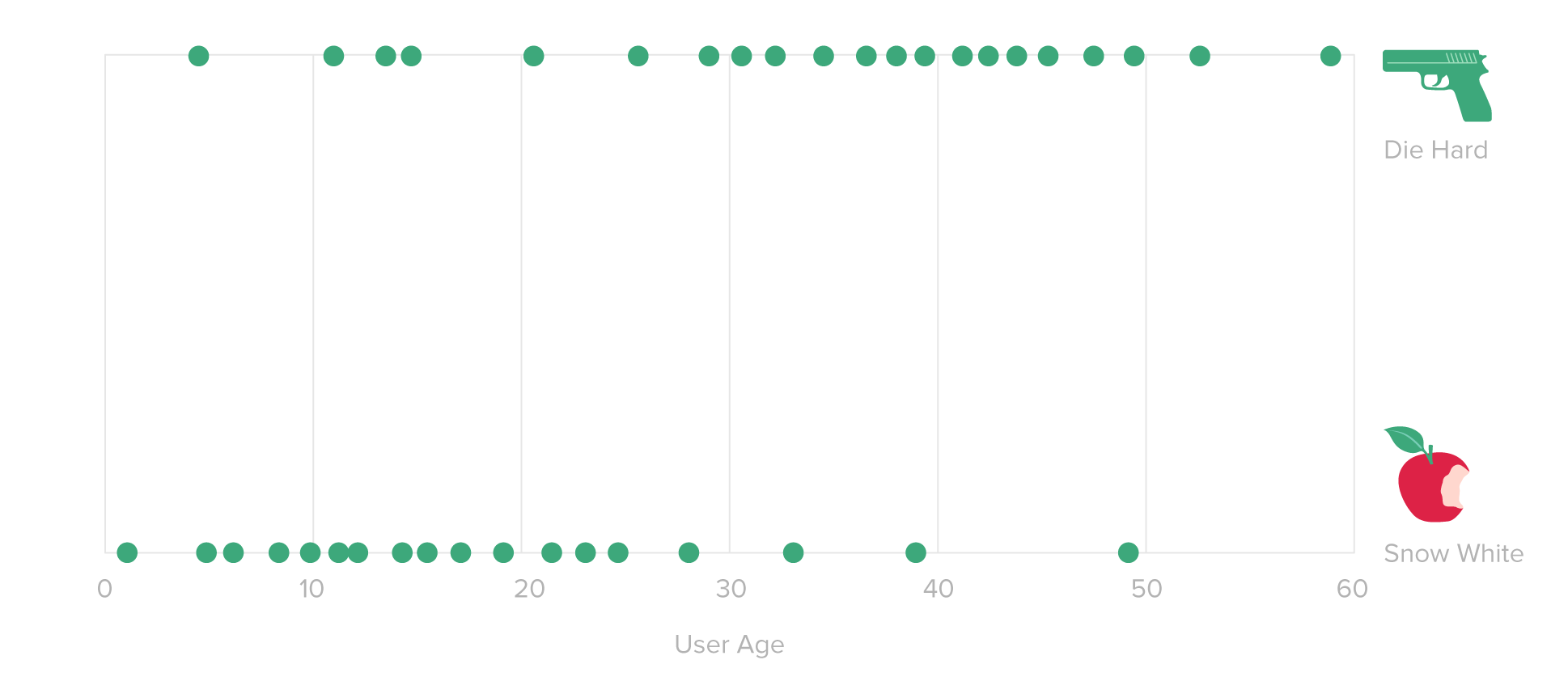
Digamos que solo hay dos películas en Netflix: Die Hard y Snow White. Y solo tenemos un punto de datos de sucesor para usar al determinar cuál de estas películas sugerir: qué época tiene el espectador. Queremos examinar qué película sugerir a un pequeño de 32 primaveras.
Recopilamos datos de cincuenta usuarios sobre su época y si les gustaba más Die Hard o Snow White. Así es como se ven los datos:

Puede ser claro a simple pinta que los espectadores mayores tienden a preferir Die Hard, y los más jóvenes prefieren Blancanieves. Pero no es obvio qué hacer con nuestro hijo de 32 primaveras. Así que le decimos a un software de estadísticas como SPSS que trace una ruta o curva, que resume lo que nos dicen estos datos. Los resultados podrían estar así:

Este ejemplo extremadamente simple, pero perfectamente válido, de un cálculo de enseñanza involuntario se conoce como regresión abastecimiento. Utiliza una función logarítmica para estimar la relación entre una variable continua (época) y una binaria (qué película). Puedes acertar más sobre la regresión abastecimiento aquí.
La interpretación de esta ruta es la posterior: a cualquier época dada, da la mejor suposición de la computadora sobre la probabilidad de qué película preferiría el sucesor (siendo 0 una preferencia absoluta por Blancanieves, 1 preferencia absoluta por Die Hard).
Entonces, para un sucesor de 32 primaveras, este maniquí nos dice que hay un 40 % de posibilidades de que este sucesor prefiera Blancanieves y un 60 % de que prefiera Die Hard. Die Hard lo es.
Críticamente, cualquier maniquí como este además dará una estadística que explique la fuerza de la relación entre cada variable independiente y la dependiente. En otras palabras, por otra parte de su sugerencia de película, la computadora además nos dice qué tan bueno es un predictor de qué película le gustará al sucesor.
Esperar. ¿Cómo sabe la máquina dibujar una ruta así?
Para problemas complejos: prueba y error. Aquí es donde el poder de enumeración de una máquina es importante. A diferencia del ejemplo previo, que teóricamente podría resolverse a mano, la mayoría de los problemas de enseñanza involuntario tratan con cientos o miles de variables de entrada. No hay una respuesta “correcta” para estas preguntas, solo una “mejor” respuesta. Para estimar el peso ideal de cada variable de entrada, los programas de enseñanza involuntario probarán un posible esquema de ponderación, lo probarán contra los datos para ver qué tan mal estuvo, harán un ajuste y lo intentarán una y otra vez. Esta forma iterativa de fuerza bruta de resolver problemas es como memorizar cuándo dejar de engullir helado. Cuando eres peque, siempre comes en exceso y te sientes enfermo. A medida que adquiera más experiencia comiendo helado, se acercará cada vez más a conocer la cantidad “óptima” que debe consumir, gracias a la simple prueba y error.
¿Cómo se puede utilizar Machine Learning para detectar fraudes?
El mismo proceso que usa Netflix para gestar recomendaciones de películas personalizadas se puede aplicar para detectar fraudes: recopile una gran cantidad de datos históricos sobre transacciones legítimas y fraudulentas, luego dígale a una computadora que encuentre qué puntos de datos (o combinaciones de puntos de datos) son más importantes, y cómo se deben pesar.
El primer paso es más tratable decirlo que hacerlo; para construir un maniquí de enseñanza involuntario preciso, necesita MUCHOS datos. Google invirtió cientos de millones de dólares en satisfacer a las personas para que condujeran, con el fin de acumular suficientes datos sobre rutas y tráfico para desarrollar el cálculo de enseñanza involuntario detrás de Google Maps. Muchas empresas emergentes que esperan utilizar soluciones de enseñanza involuntario se quedan sin fondos en el proceso de resumen de datos suficientes para avalar la precisión de su maniquí.
Riskified adoptó un enfoque reformador para este problema. Nos ofrecimos a revisar los pedidos riesgosos de los comerciantes, los que planeaban rehusar de todos modos. Solo pagarían por los pedidos que aprobáramos, y cualquier error que cometiéramos estaba respaldado por nuestra seguro de contracargo. No hubo inconveniente para que los comerciantes nos probaran. Al revisar y etiquetar manualmente los pedidos durante un año, acumulamos suficientes datos para desarrollar nuestros primeros modelos de enseñanza involuntario.
Para cada pedido que procesamos, tenemos miles de puntos de datos, incluidos algunos que recopilamos nosotros mismos: nuestra baliza web patentada recopila información sobre el comportamiento de los compradores mientras están en los sitios de comercio electrónico de nuestros clientes, y usamos tecnología desarrollada internamente para determinar si o no, un comprador está utilizando un servidor proxy.
Aunque nuestros analistas humanos son extremadamente precisos en la revisión de fraudes, tener una computadora para hacer esta tarea tiene ventajas:
-
- Es escalable: crucial para una empresa en rápido crecimiento.
-
- Es mas rapido. Incluso las mejores mentes necesitan unos minutos para tomar una intrepidez de pedido. Las computadoras tardan milisegundos.
- Las computadoras se pueden recalibrar mucho más fácilmente.
Es la idea de la recalibración, en particular, lo que hace que el enseñanza involuntario sea tan adecuado para la detección de fraudes. Y ahí es donde entra en distracción el enseñanza profundo.
Educación profundo, redes neuronales y detección de fraude
La vanguardia del enseñanza involuntario es lo que se conoce como “enseñanza profundo”. Esta es una forma sofisticada de resolución de problemas, que utiliza una estructura de enseñanza inspirada en el cerebro humano.
En esta formulación, una muestra parte de una serie de nodos que la clasifican según criterios muy básicos. Luego de esta clasificación, viaja a la segunda serie de nodos, que lo clasifica según especificaciones un poco más estrechas. Este proceso se repite hasta que la computadora llega a una ‘intrepidez’.

La delantera esencia de esta configuración es su capacidad superior para formarse de sus propios errores. Si perfectamente los programas de enseñanza involuntario más tradicionales tienden a sufrir rendimientos decrecientes a medida que procesan más y más datos, es probable que las redes neuronales “aprendan” casi tanto de la muestra milmillonésima como de la millonésima.
Esto hace que el enseñanza profundo sea muy útil en el campo de la prevención del fraude. A diferencia de las sugerencias de películas, donde es poco probable que los factores que influyen en las preferencias de los clientes cambien drásticamente, los estafadores están constantemente perfeccionando su oficio. Cuando los sistemas de prevención rechazan las órdenes de los estafadores, no vuelven a intentar lo mismo; descubren por qué fueron atrapados y tratan de adaptarse. Por esta razón, una utensilio de prevención de fraudes que sea lenta para adaptarse a la nueva información tendrá dificultades para examinar los pedidos de guisa efectivo.
Espero que haya antitético útil esta preparación al enseñanza involuntario y sus aplicaciones para la detección de fraudes. Para obtener más información sobre cómo la opción de fraude de enseñanza profundo de Riskified puede ayudar a su empresa a detectar el fraude de guisa más efectivo, solicite una demostración de nuestro producto.